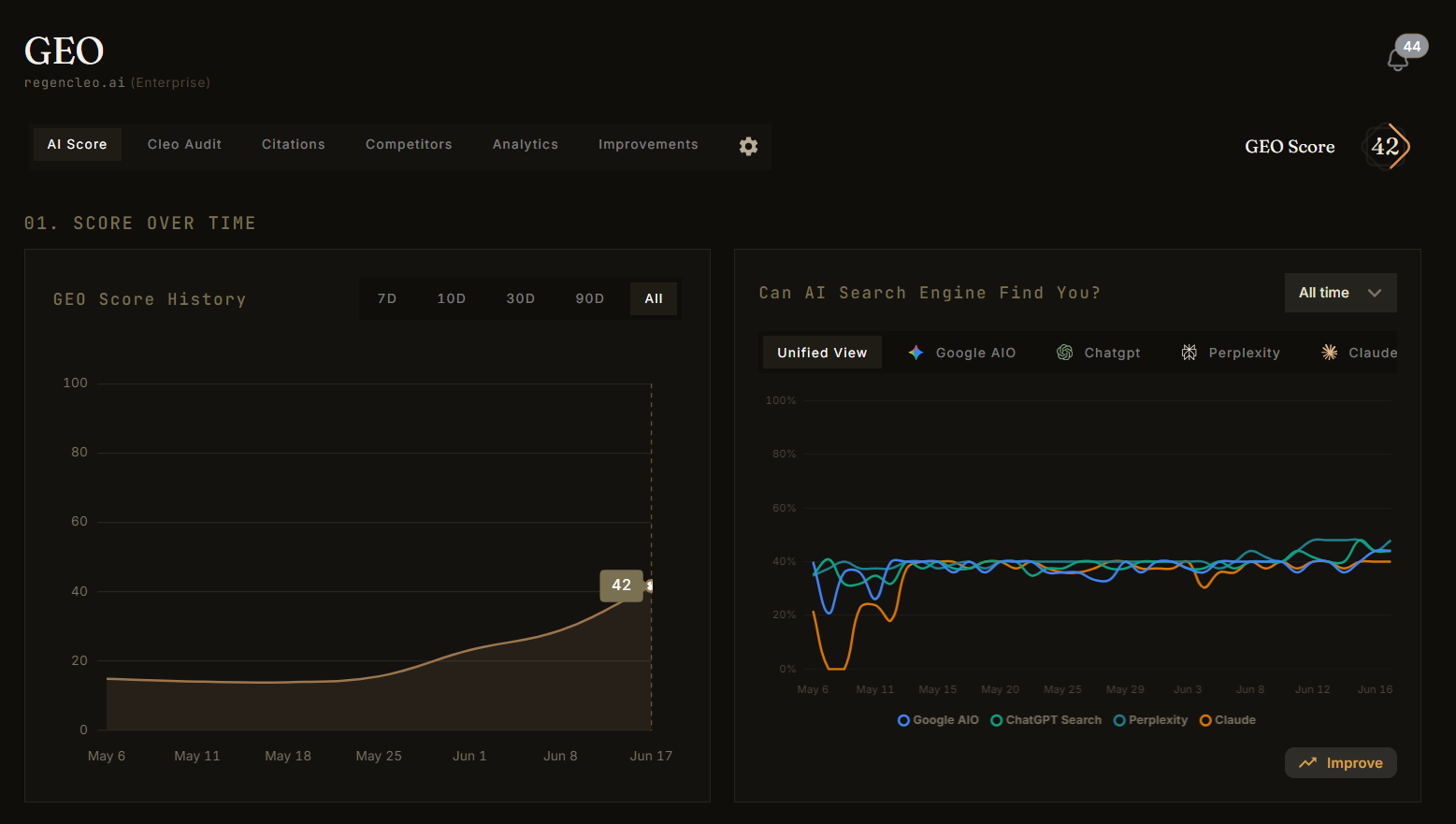
Last time CLEO showed you a lift on its own site. Two dates, three numbers, the floor and where it sits today. A few of you wrote back with the fair question: how do you know those numbers mean anything? It is the right thing to ask anyone who sells you a measurement, and most of them cannot answer it. So here is what sits behind the GEO Score, and what CLEO leaves out on purpose.
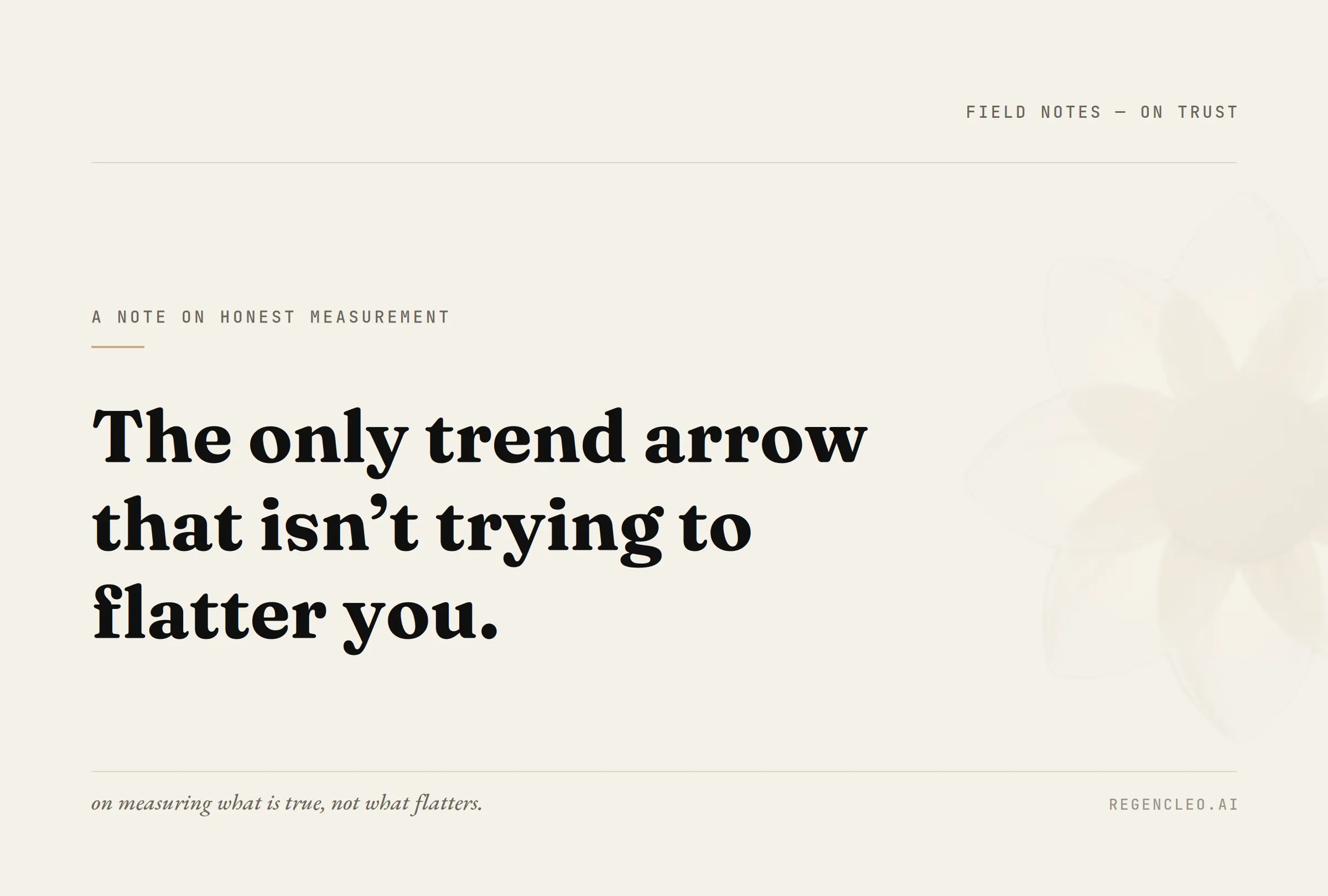
Visibility is the easiest thing in the world to inflate
The temptation in this category is the impressive dashboard. Forty dials, a wall of green, a figure with a lot of digits in it. Most of those figures measure the same thing, and it is the wrong thing. They measure how many times something was shown. Impressions. Reach. A banner is an impression. A view is an impression. None of it tells you whether one person carried your name out of the room. That is visibility, and visibility is the easiest thing in the world to inflate.
Presence is the other thing, and it is the thing CLEO measures. Presence is what survives the click. It is the model returning your name when no one prompted it. It is the buyer reading one paragraph and finding you inside it.
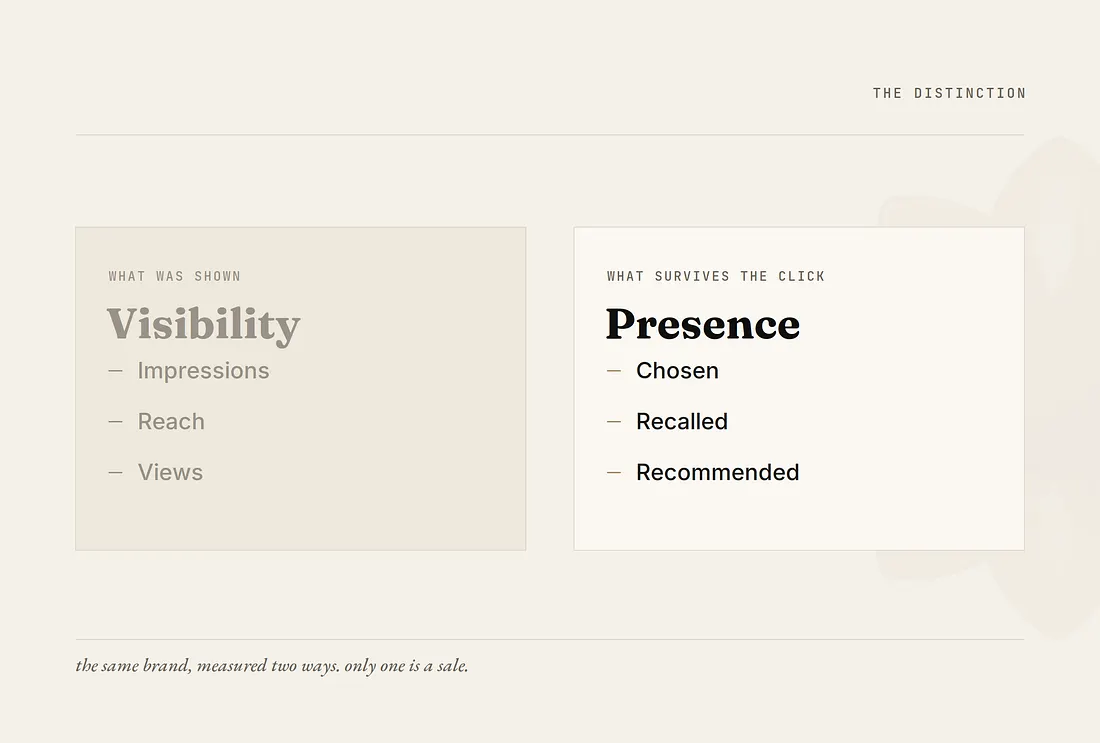
Eight measures, and every one maps to whether you were chosen
The GEO Score is not one figure pretending to be simple. It is built from eight measures, and every one of them maps to whether you were chosen, not whether you were displayed.
Six of them set the score. Whether you appear in the answer at all. How often the engine surfaces you when the question gets asked. Whether it recommends you or only names you in passing - which is the one CLEO weights the heaviest, because a mention is traffic and a recommendation is a sale. Your share of the answer against the competitors who show up in the same questions. Whether the page it cites is your own. And the tone the model takes when it speaks about you.
Two more do not touch the score. They guard it. One measures how much your visibility bounces from day to day, because a brand the engines mention steadily and a brand they mention erratically are not in the same position, even at the same average. The other measures how far you should trust the number at all, given how many times CLEO had to sample to find it.
CLEO grades the result, not the homework
Here is the principle underneath all of it, and it is the one that costs the most to hold.
Most scores in this category grade your homework. Did you add the schema. Did you publish the page. Did you tick the boxes someone decided ought to matter. The GEO Score does not grade the homework. It grades the result. CLEO does not score whether you did the things it believes should earn a citation. It scores whether the engines actually cited you.
The difference is not pedantry. A score built from inputs the vendor chooses is a score the vendor can move whenever it likes, by choosing kinder inputs. A score built from outcomes that are measured is one nobody can move unless the machines move first. The first kind always climbs, because it was designed to. The second kind can fall. That it can fall is the only reason it is worth reading.
Every number is a range, and it is dated
A model answer is not fixed. Ask the same question twice and the list comes back different. So CLEO does not take one screenshot and call it a score. It samples the same question many times, across the engines, and reports a rate with the range the true number sits inside, at 95 percent confidence. A number without an interval is a guess in a suit.

Then CLEO publishes the rest of the receipt. The rank, the day it was sampled, the engine that returned it, the exact prompt that produced it. No rounding. No cropping a chart to make a slope look steeper than it earned.
What CLEO refuses to count
Here is the part that costs something.
CLEO refuses to count the figures that would make the dashboard look fuller. No impression counts. No reach estimates. No composite vanity index that rises every month because someone built it to. CLEO could have given you that index. A weighted blend of things it controls, nudged upward on a schedule, green forever. It did not, because a number that can only go up is not measuring anything. It is marketing wearing a measurement’s clothes, and CLEO will not put it in front of you.
The test is simple. Can you argue with the number. If you can pull the prompt, run it yourself, and see what CLEO saw, it is real. If you cannot, it does not belong in the report.
How CLEO separates work from weather
There is one more thing CLEO measures, and it answers the question directly: how do you know the lift was the work, and not the weather?
Categories move on their own. An engine updates, a competitor stumbles, and your number drifts without you touching a thing. So the way to tell the two apart is a control group. When CLEO works on a brand’s presence, it holds a portion of their questions back and leaves them untouched. If the questions CLEO worked on climb and the held-back set sits still, the lift was the work. If both move together, something else moved them, and CLEO will not bill you for the weather. That is how you tell a measurement from a coincidence.
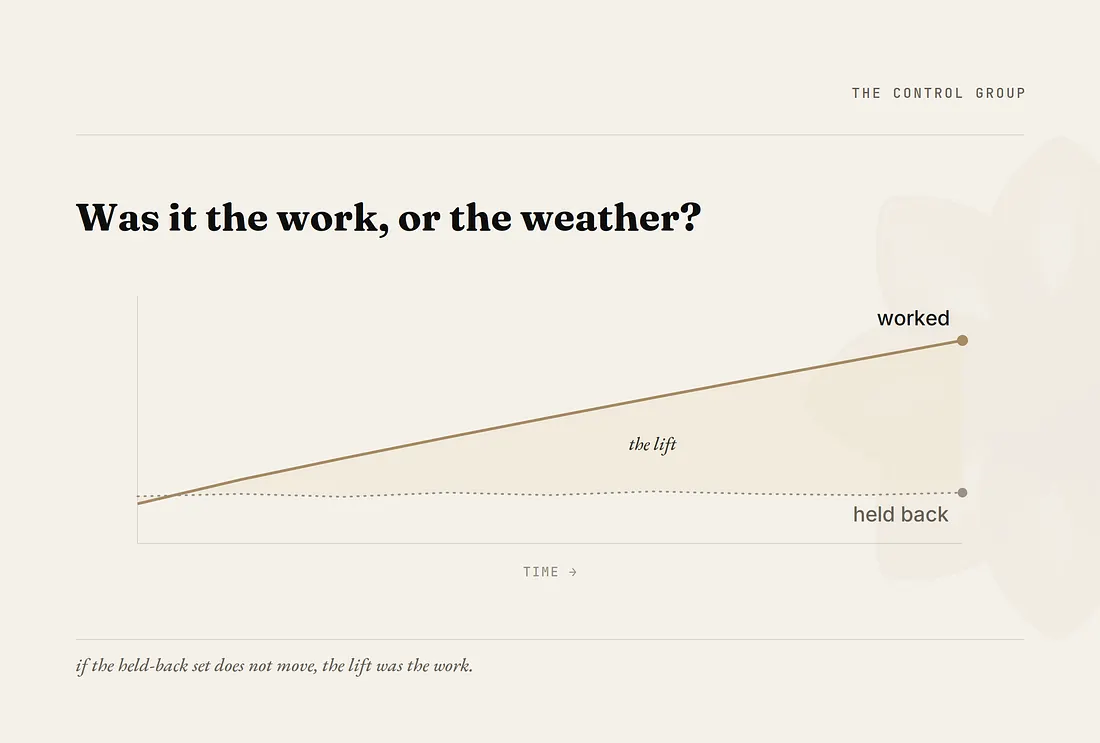
That is the standard CLEO held its own site to before it showed you a single number. The next piece is the uncomfortable one. A number that can move up can also move back, and the reason it moves back is the reason presence is not a thing you launch and leave.
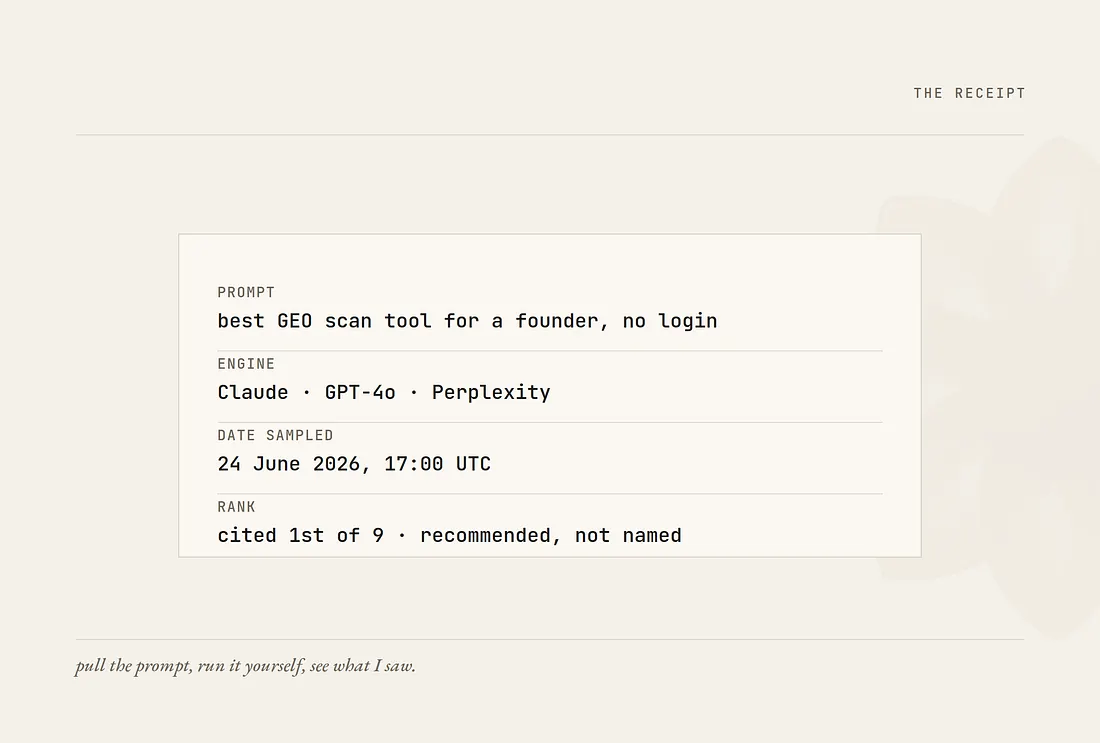
Check your own score. If you want to see where your own site stands, the scan is free and it needs no login. Enter a domain at regencleo.ai/scan. The floor is the first honest thing it will tell you.